зміст:
- Як позбутися дублів сторінок
- З чого почати видалення дублів сторінок
- Способи вирішення виявлених проблем
- Якщо немає можливості прибрати дублі сторінок…
Як позбутися дублів сторінок
Після того як були виявлені копії сторінок веб-ресурсу, потрібно вирішити, як прибрати дублювання. Адже навіть якщо подібних повторень трохи, це все одно негативно позначиться на рейтингах Вашого веб-ресурсу – пошуковики можуть покарати Вас зниженням позицій. Тому важливо прибрати дублікати сторінок незалежно від їх кількості.
З чого почати видалення дублів сторінок
Для початку рекомендується виявити причину, по якій з'явилося дублювання контенту. Найчастіше це:
- Помилки при формуванні структури веб-ресурсу.
- « Проробки » деяких сучасних движків для сайтів, які при неправильних настройках досить часто автоматично генерують копії і зберігають їх під різними адресами.
- Неправильні настройки фільтрів пошуку по сайту.
Способи вирішення виявлених проблем
Після з'ясування причини, по якій з'явилося дублювання, і її усунення потрібно прийняти рішення щодо того, як прибрати дублі сторінок. У більшості випадків підійде один з цих методів:
- Видалити дублі сторінок вручну. Цей метод підійде для невеликих веб-ресурсів, що містять до 100 – 150 сторінок, які цілком можна перебрати самому.
- налаштувати robots.txt. Підійде, щоб приховати дублікати сторінок, індексування яких ще не проводилося. Використання директиви Disallow забороняє ботам заходити на непотрібні сторінки. Щоб вказати боту Яндекса на те, що йому не слід індексувати сторінки, що містять в URL « stranitsa », потрібно в robots.txt додати:

- Використовувати мета-тег « noindex ». Це не допоможе видалити дублі сторінок, але приховає їх від індексування, як і в попередньому способі. Прописується в HTML-коді сторінки ( в розділі head ), про яку повинні « забути » пошуковики, в такому вигляді:

При цьому є один нюанс – якщо сторінка-дублікат вже з'являється в результатах видачі, то вона буде продовжувати це робити до повторної індексації, яка могла бути заблокована в файлі robots.txt.
- Видалення дублів сторінок, використовуючи перенаправлення 410. Непоганий варіант замість попередніх двох способів. Повідомляє зайшов в гості робота пошукача про те, що сторінки не існує і відсутні дані про альтернативний документі. Вставляється в файл конфігурації сервера .htaccess у вигляді:
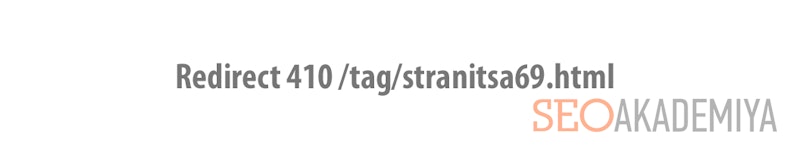
В результаті при спробі зайти за адресою сторінки-дубля Ви побачите:
- Вказати канонічну сторінку для індексації. Для цієї мети використовується атрибут rel = ” canonical ”. Додається в head HTML-коду сторінок, які є непотрібними копіями.

Це не допоможе фізично позбутися дублів сторінок, а лише вкаже ботам пошукових систем канонічну ( вихідну ), якій потрібна індексація.
- Склеювання сторінок. Для цього використовується перенаправлення 301. Подібний варіант також не допоможе прибрати дублікати сторінок, але дозволить передати потрібній сторінці до 99% зовнішнього і внутрішнього посилальної ваги. приклад:

Якщо немає можливості прибрати дублі сторінок...
... або ж Ви не хочете їх видаляти, можна хоча б убезпечити сторінки, які за допомогою внутрішньої перелінковки пов'язані з ними. Для цього використовується атрибут rel = « nofollow ». Якщо прописати його в посиланнях, вони більше не будуть передавати вагу.
![]()
Тепер Ви знаєте достатньо способів того, як прибрати дублі сторінок. Якщо вміло їх комбінувати, Ви зможете домогтися, щоб не залишилося жодного прецеденту дублювання контенту. Тільки після цього можна розраховувати на максимальну ефективність просування Вашого сайту.
Якщо залишилися питання по даній темі, не забудьте їх задати в коментарях!




