
Содержание:
- Как избавиться от дублей страниц
- С чего начать удаление дублей страниц
- Способы решения выявленных проблем
- Если нет возможности убрать дубли страниц…
Как избавиться от дублей страниц
После того как были обнаружены копии страничек веб-ресурса, нужно решить, как убрать дублирование. Ведь даже если подобных повторений немного, это все равно негативно скажется на рейтингах Вашего веб-ресурса – поисковики могут наказать Вас снижением позиций. Поэтому важно убрать дубликаты страниц независимо от их количества.
С чего начать удаление дублей страниц
Для начала рекомендуется выявить причину, по которой появилось дублирование контента. Чаще всего это:
- Ошибки при формировании структуры веб-ресурса.
- «Проделки» некоторых современных движков для сайтов, которые при неправильных настройках довольно часто автоматически генерируют копии и хранят их под разными адресами.
- Неправильные настройки фильтров поиска по сайту.
Способы решения выявленных проблем
После выяснения причины, по которой появилось дублирование, и ее устранения нужно принять решение касательно того, как убрать дубли страниц. В большинстве случаев подойдет один из этих методов:
- Удалить дубли страниц вручную. Этот метод подойдет для небольших веб-ресурсов, содержащих до 100–150 страничек, которые вполне можно перебрать самому.
- Настроить robots.txt. Подойдет, чтобы скрыть дубликаты страниц, индексирование которых еще не проводилось. Использование директивы Disallow запрещает ботам заходить на ненужные страницы. Чтобы указать боту Яндекса на то, что ему не следует индексировать странички, содержащие в URL «stranitsa», нужно в robots.txt добавить:

- Использовать мета-тег «noindex». Это не поможет удалить дубли страниц, но скроет их от индексирования, как и в предыдущем способе. Прописывается в HTML-коде странички (в разделе head), про которую должны «забыть» поисковики, в таком виде:

При этом есть один нюанс – если страница-дубликат уже появляется в результатах выдачи, то она будет продолжать это делать до повторной индексации, которая могла быть заблокирована в файле robots.txt.
- Удаление дублей страниц, используя перенаправление 410. Неплохой вариант вместо предыдущих двух способов. Уведомляет зашедшего в гости робота поисковика о том, что странички не существует и отсутствуют данные об альтернативном документе. Вставляется в файл конфигурирования сервера .htaccess в виде:
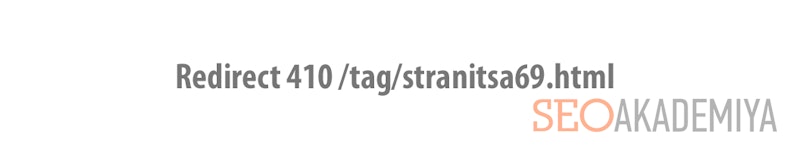
В результате при попытке зайти по адресу страницы-дубля Вы увидите:
- Указать каноническую страничку для индексации. Для этой цели используется атрибут rel=”canonical”. Добавляется в head HTML-кода страничек, которые являются ненужными копиями.

Это не поможет физически избавиться от дублей страниц, а лишь укажет ботам поисковых систем каноническую (исходную), которой нужна индексация.
- Склеивание страниц. Для этого используется перенаправление 301. Подобный вариант также не поможет убрать дубликаты страниц, но позволит передать нужной страничке до 99% внешнего и внутреннего ссылочного веса. Пример:

Если нет возможности убрать дубли страниц...
... или же Вы не хотите их удалять, можно хотя бы обезопасить странички, которые при помощи внутренней перелинковки связаны с ними. Для этого используется атрибут rel=«nofollow». Если прописать его в ссылках, они больше не будут передавать вес.
![]()
Теперь Вы знаете достаточно способов того, как убрать дубли страниц. Если умело их комбинировать, Вы сможете добиться, чтобы не осталось ни единого прецедента дублирования контента. Только после этого можно рассчитывать на максимальную эффективность продвижения Вашего сайта.
Если остались вопросы по данной теме, не забудьте их задать в комментариях!

Павел Шульга
Основатель и идейный лидер Академии SEO.Предприниматель, владелец 8-ми работающих бизнесов, создатель и спикер обучающих курсов Академии SEO. Практически всю свою осознанную жизнь занимается SEO-продвижением.
В 2004 году увлекся ...




